Labs
Interactive labs
Self-contained, in-browser demos of the ideas under the hood — hypervector memory, stigmergic swarms, and tiny sequence models. Each isolates one concept and runs entirely client-side; nothing to install.
Hypervectors & reasoning
How a single agent reasons — symbols, memory, planning, and generalisation, all built from one long random vector.
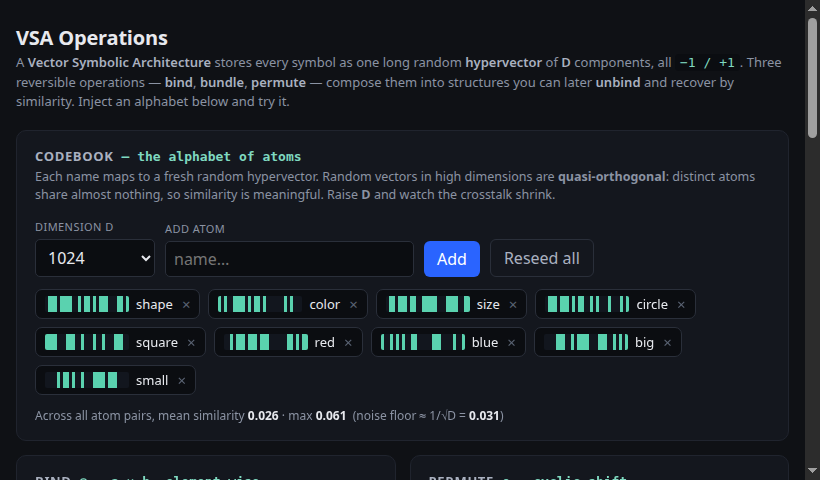
Bind, bundle, permute, and a key–value record — the whole algebra the project runs on. Inject atoms and recover them by similarity.
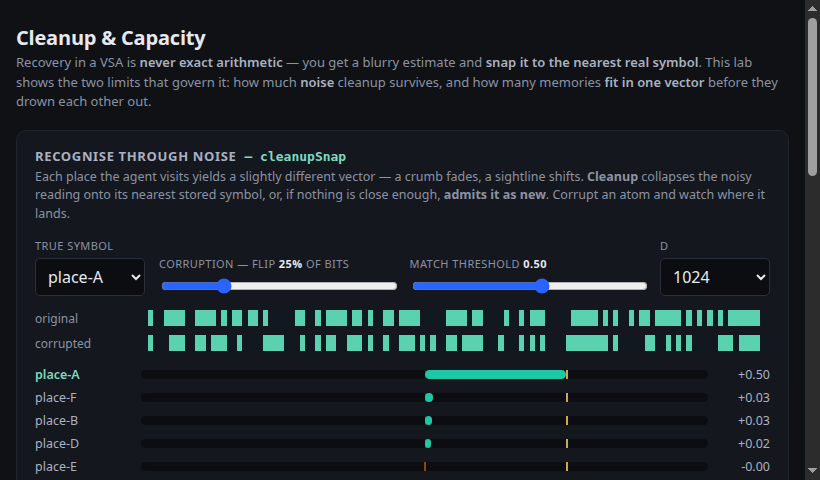
Recover a vector from noise (sim ≈ 1−2p), then watch the capacity cliff: how many memories fit in one vector before they drown out.
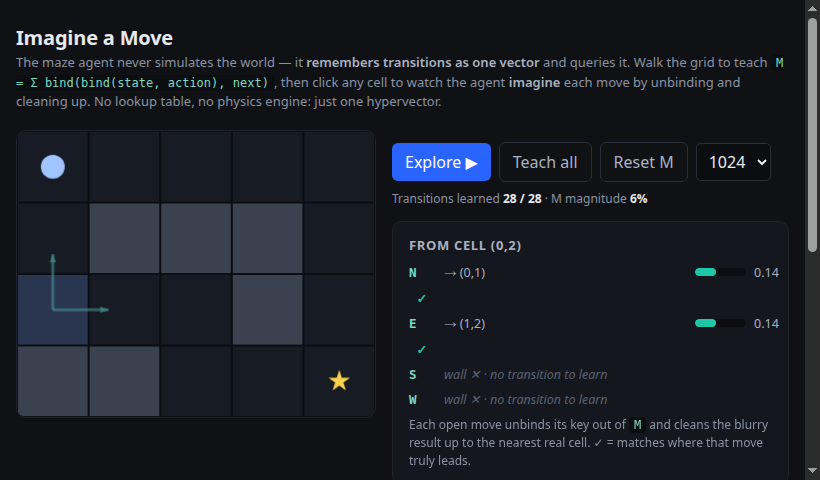
Build a forward model in one vector by walking a grid, then unbind + clean up to imagine each move before committing.
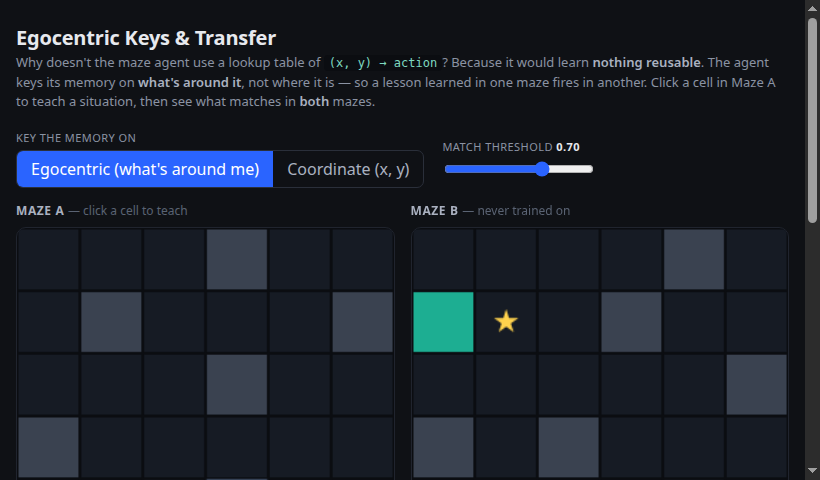
Why the agent keys on what's around it, not where it is — so a lesson learned in one maze fires in another a coordinate table couldn't touch.
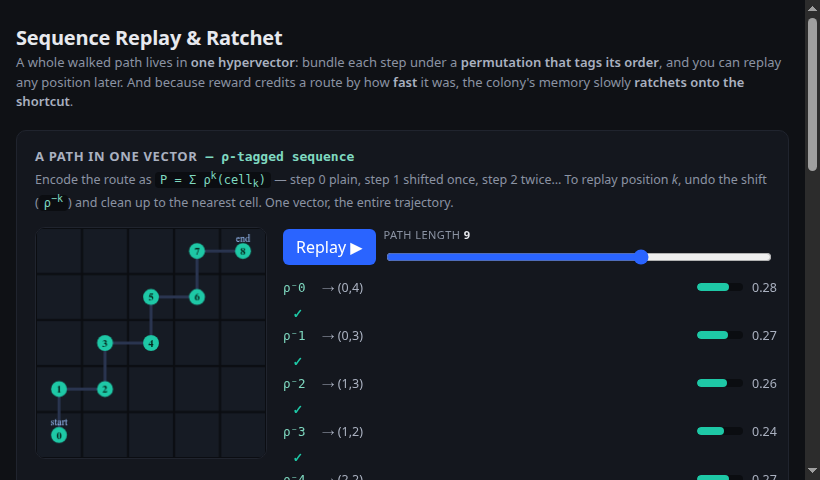
A whole walked path lives in one hypervector, replayable by position — and speed-weighted credit ratchets the colony onto the shortcut.
Swarms & stigmergy
How many agents reason together — knowledge held in an evaporating shared floor, not any head. Pheromone Foraging is pure emergence; Swarm Convergence adds success-scaling and authority for quality-controlled graph search.
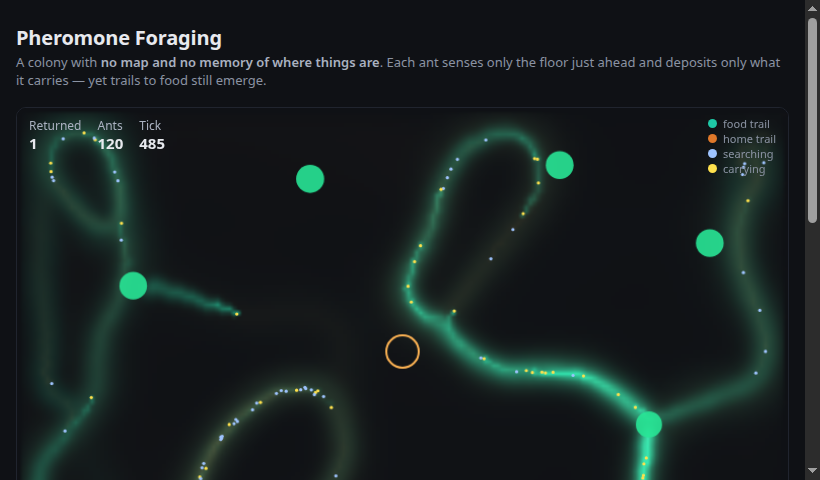
A colony finds food with no map and no memory of where anything is — only evaporating local trails. Stigmergy from first principles.

A swarm finds the exit and then shortens the route, via success-weighted deposits and authority gating. Stigmergy doing graph search.
Belief-graph fighters
A third track — from the Eddy project. A fighter's decision is a graph query: counter-rules are facts with valences, learned from outcomes, predicting from observed transitions. Three labs on the same engine — each adds one mechanism on the previous lab's substrate.

Alice has no counter-table — only (counter, counters, opponent) facts with valences. Edit the valences, watch the picks flip. Decision is a single graph scan.

Same graph, but each round's outcome nudges the used rule's valence. Run a 10-round match and watch Alice's and Bob's graphs diverge into two different policies.

Alice observes Bob's move-to-move transitions, predicts what comes next, and counters the prediction instead of the observation. Toggle predictive on/off mid-match.
Belief dynamics
How beliefs change over time without anyone editing them. Three labs on the same theme — multiplicative decay, valence bumps grounded in outcomes, and recency-and-emotion-weighted episodic replay. Same `value ± δ` shape as Valence Tuning, applied to weight, trust, and dreams.

Lyswen performs a ballad each day; between days every weight is multiplied by a fixed rate. The ledger develops shape — recent at full weight, ancient faded. Self-core identity stays pinned.

Bob advises Alice. Each time Alice successfully practices an advised stance, the (alice, taught_by, bob) valence ticks up. Advice that works earns trust; orthogonal advice doesn't.

During sleep the agent samples episodes weighted by emotion and recency, replaying their SPOs into working memory as dream fragments. The substrate the next day starts from.
Reasoning the chain
Three labs on chain reasoning — the substrate of eddy's symbolic decision layer. A schedule chain walks day-of-week to practice intent; saturation closure runs over private rules so the same event yields different beliefs; an HDC routine schema and a single surprise gate together enforce the 14% rule structurally.

Alice consults her watch, the schedule chain queries today's entry, and the motor router resolves the stance into poses. Toggle any premise off and the chain refuses to close.

Alice has the rule "attacked → threatens", Bob has none. Same event broadcasts to both; saturation runs on each private graph; only Alice derives the threat. Edit either side and replay.

An HDC schema centroid of Bob's tilling routine; a chain locks to it, a rabbit explodes, a bar fight materialises. Cosine drift fires routine_violation; the surprise gate keeps the chain individuated.
Tiny LLM
Seven labs unpacking how a transformer works, end-to-end. Tokens become vectors, vectors flow through attention, attention chains into reasoning, then drifts. Plus the missing mechanics — positional encoding, multi-head, sampling. (RAG continues the thread in Bonus.)
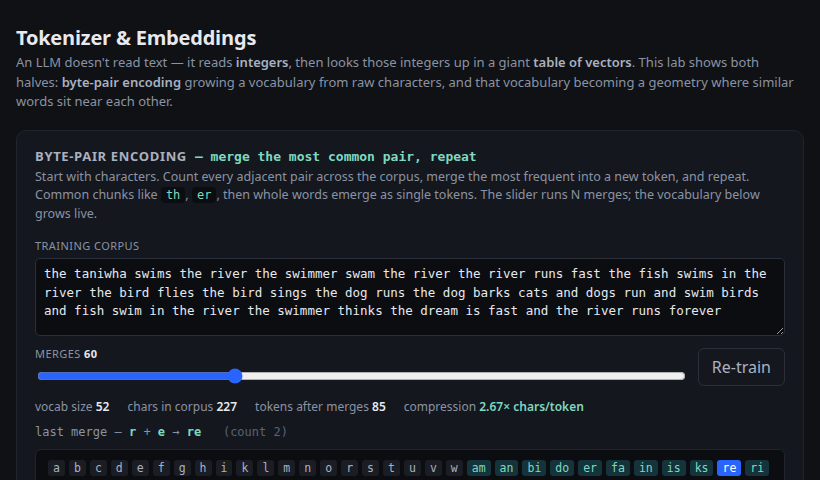
Raw characters merge into BPE tokens, those tokens look up rows of an embedding matrix, and a 2D PCA shows them clustering by meaning.
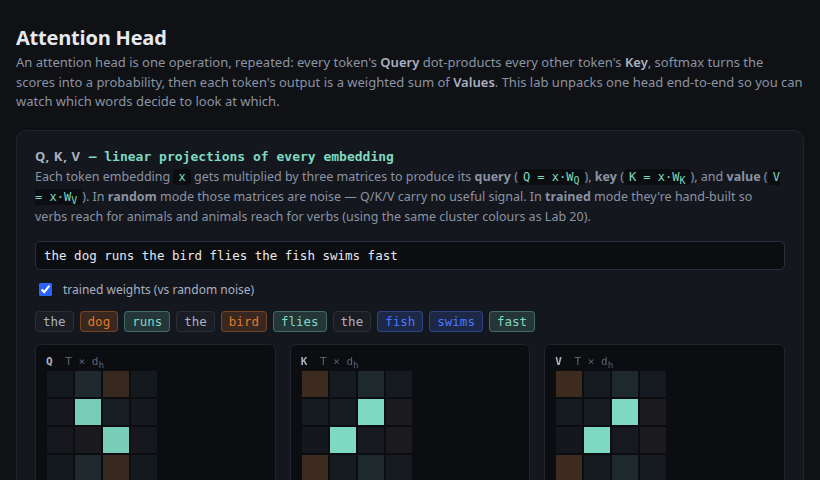
One head end-to-end: hand-crafted W_Q/W_K/W_V show verbs visibly attending to animals. Toggle trained vs random to see the geometry collapse.
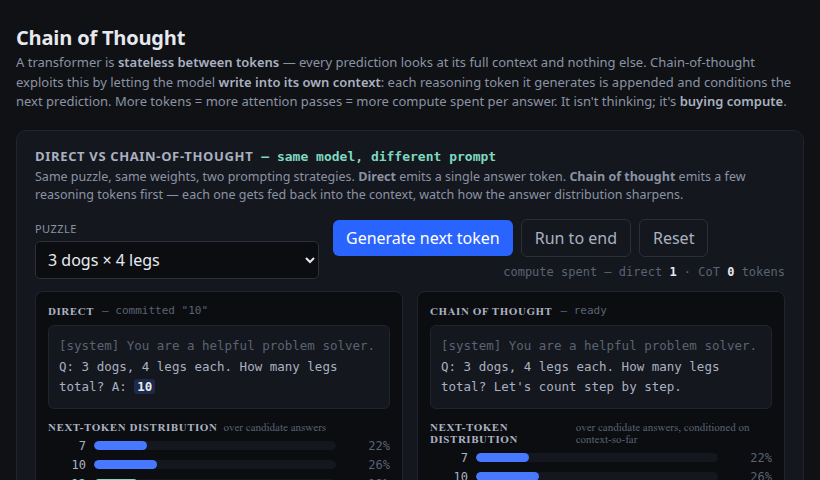
Direct vs CoT side-by-side. Each emitted reasoning token gets fed back into context and sharpens the answer distribution — the textbook induction-head jump.
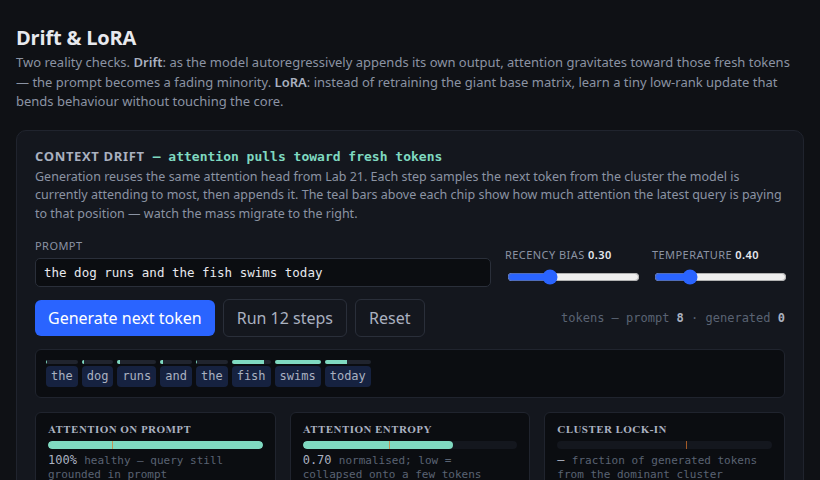
Two reality checks. Watch attention drift to the model's own tokens as generation continues, then bend the next-token distribution with a tiny low-rank adapter.
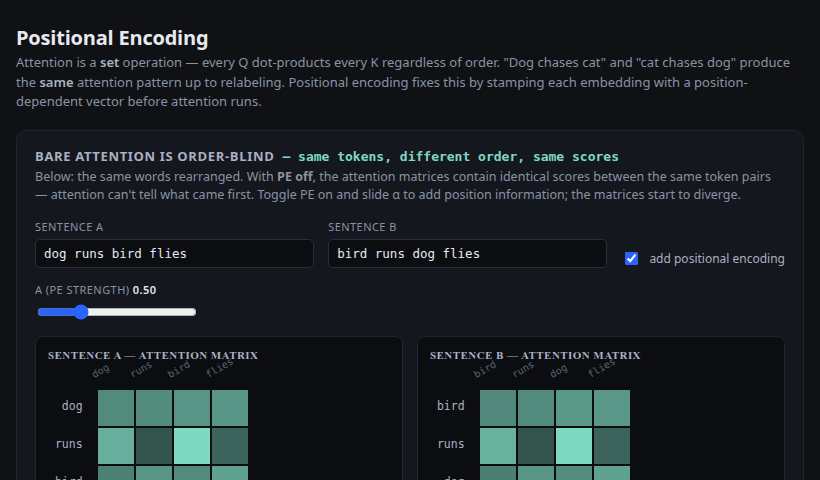
"Dog runs bird" vs "bird runs dog" — same words, different order. Bare attention cannot tell; add sinusoidal PE and the matrices diverge.
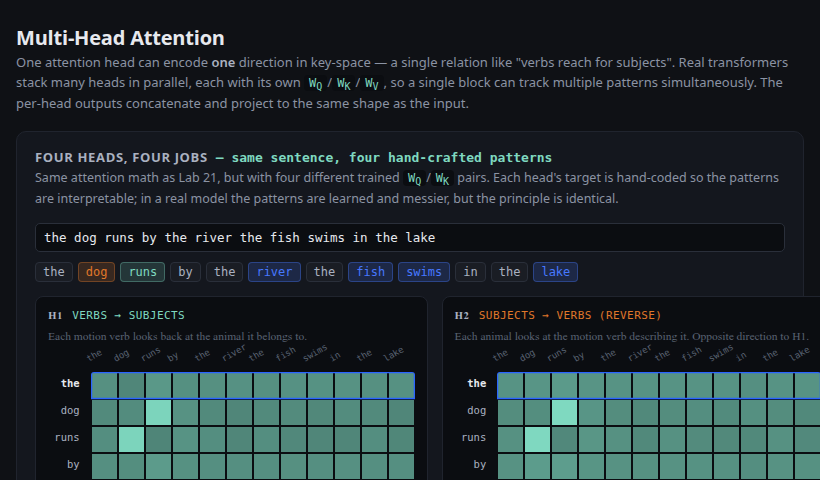
Four heads, four jobs running in parallel — verbs→subjects, subjects→verbs, verbs→water-nouns, water↔animals. Each captures one direction the others can't.
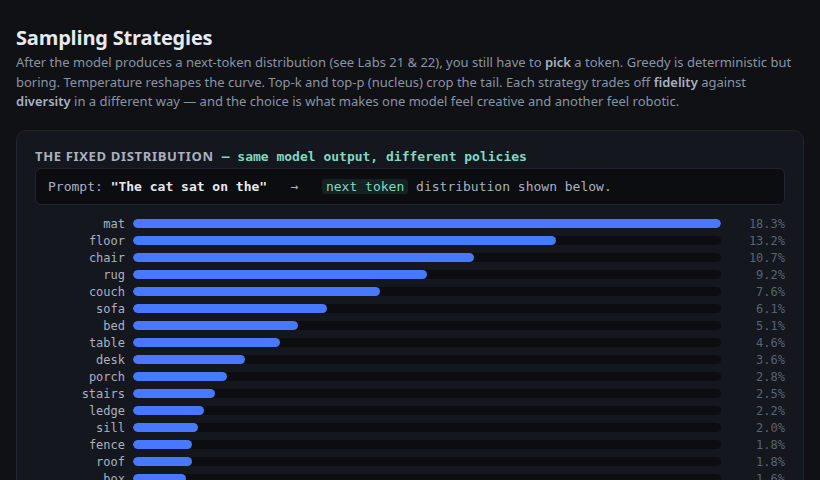
Same fixed distribution, four ways to pick a token. Roll 200× to see the empirical distribution each strategy actually produces.
Bonus · playground
A tangent from a chat about how small a toy LLM can get — the same forward-model and temperature ideas as above, applied to notes you can hear: as an exact count table, as a single hypervector, and as a two-level coarse-to-fine sketch. Plus a RAG demo that pairs with the Tiny LLM track.
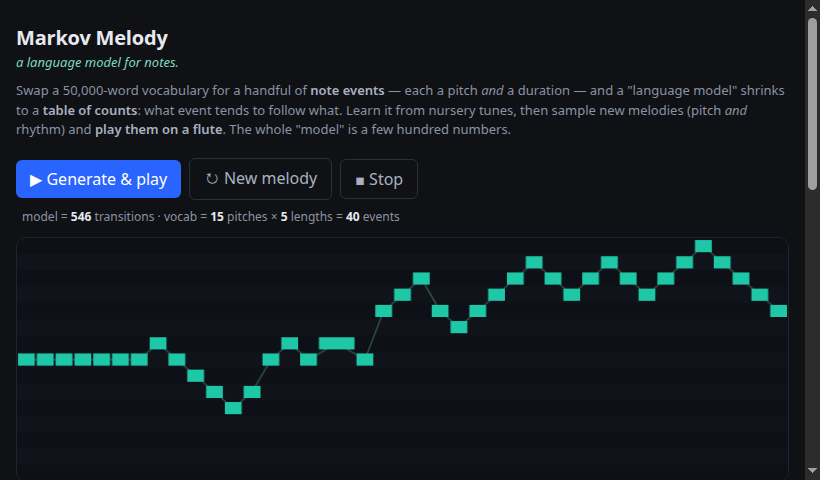
A "language model" for note events — a kilobyte of counts learned from nursery tunes, sampled into new melody + rhythm and played on a flute.
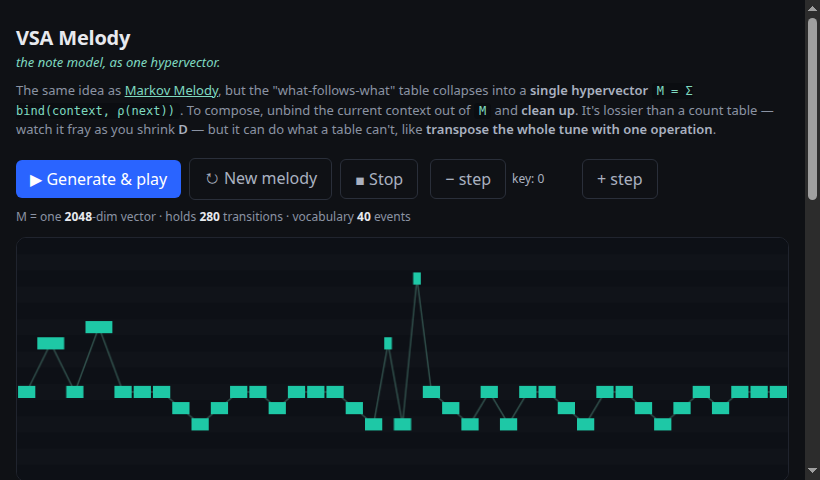
The same note model as one hypervector instead of a table — unbind + clean up to compose. Lossy as D shrinks, but it can transpose with a single ρ.
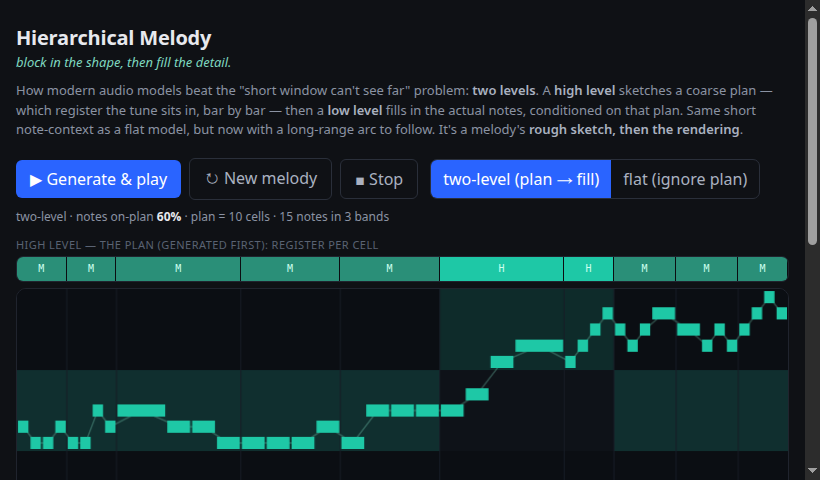
Two levels: a high model sketches the register plan, a low model fills in the notes — coarse-to-fine, like a rough sketch then rendering.
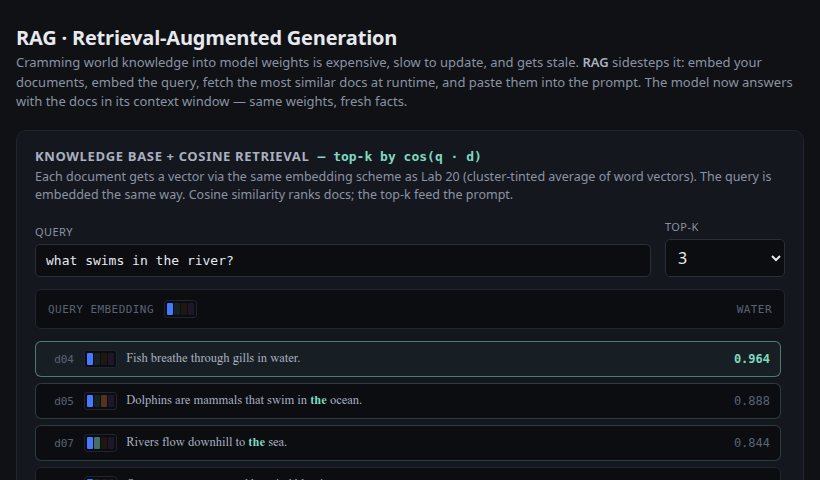
Embed the query, cosine-rank a tiny knowledge base, splice top-k into the prompt. Same weights, fresh facts.
Each lab is a single self-contained HTML file — vanilla JS + canvas, no dependencies. They open in a new full-screen view; use your browser's back button to return here.